2026年4月3日
諸角 昌宏
本ブログは、CSAジャパンとしての正式な見解ではなく、あくまで筆者の個人的な意見としてまとめたものである。しかしながら、この問題はクラウドセキュリティに関わる人に幅広く関係することとして、このCSAジャパン・ブログに掲載させていただく。皆さんの屈託のない意見をいただければ幸いである。
本ブログは、3月26日に公開した「VPNは本当に危ないのか」の続編として、VPNの設計思想の問題に対してZTNAが提供している「ダークIP」について掘り下げてみる。なお、前のブログに対して「VPN対策はゼロトラストではないのか」という質問が寄せられた。ここでは、ゼロトラスト(ZT)とゼロトラストネットワークアクセス(ZTNA)の違いについての説明は行わないが、前のブログおよびこのブログで説明しているのは、ZTではなくZTNAであるということを述べておく。
まず、VPNのリスクについておさらいする。VPNのリスクは性質の異なる三つの層に分かれている。
- 第1層:製品脆弱性(CVE)のリスク——VPN製品自体に脆弱性が発見されるたびに、パッチ適用までの間が無防備な状態になる
- 第2層:認証情報管理のリスク——漏洩したパスワードやMFA未設定のアカウントが侵入口になる
- 第3層:設計思想の欠陥——公開ポートによるアタックサーフェスの恒常的な存在と、認証後のラテラルムーブメントを許容する構造
「ダークIP」は、主にこの第3層「設計思想の欠陥」を解決するアプローチである。第1層・第2層のリスクはパッチ管理やMFA強化で対処する一方、ダークIPは公開ポートによるアタックサーフェスを根本から排除することで第3層の問題に対処する。さらにその副次的な効果として、公開ポートが存在しなくなることにより第1層のCVE直接攻撃も成立しにくくなる。ただしダークIPの効果はすべての脅威に及ぶわけではなく、防げる脅威と防げない脅威がある。本ブログではその範囲を整理していきたい。
ダークIPの仕組み
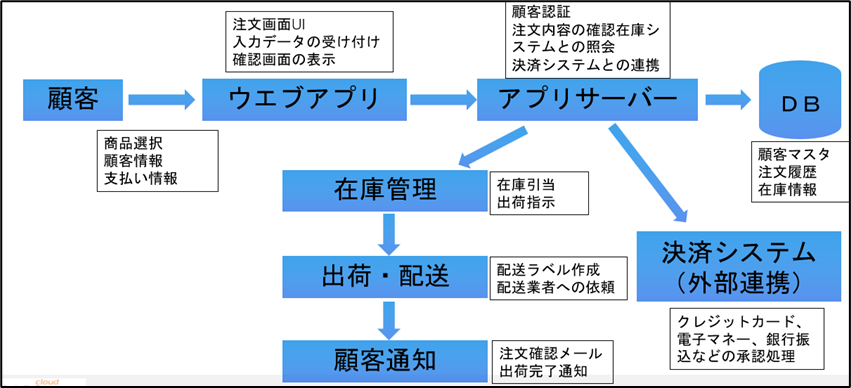
ZTNAの重要な特徴としての「ダークIP」は、サーバーや内部リソースのIPアドレスをインターネット上から不可視化する仕組みである。
VPNではアプライアンスが常時インターネットに公開されたポートを持っている。攻撃者はスキャンエンジンを用いて公開されているポートを見つけ、脆弱性の有無を調べて攻撃を仕掛ける。「公開ポートが存在する=攻撃の入口が常に存在する」という構造になる。 ZTNAのダークIPはこの構造を根本から変えている。内部リソースはZTNAのコネクタ(ゲートウェイ側に設置)を介してのみアクセス可能であり、サーバーのIPアドレス自体がインターネット上に露出しない。攻撃者がスキャンしても存在自体が見えず、直接攻撃の糸口をつかみにくくなる。つまり、以下のような関係になる。
- VPN: 外部 → 公開ポート(常時露出)→ 内部ネットワーク
- ZTNA: 外部 → ZTNAゲートウェイ(認証・ポリシー評価)→ 内部リソース(IPアドレス非公開)
なお、ダークIPはアタックサーフェスを大幅に削減することができるが、すべての攻撃を防ぐことができるわけではない。以下でその効果の範囲を整理してみる。
ダークIPで防げること
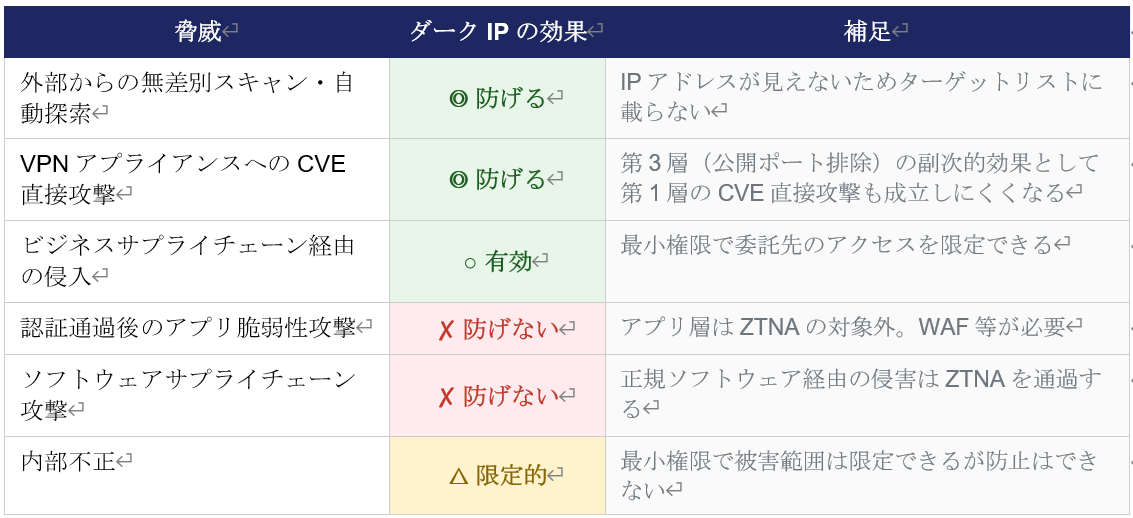
外部からの無差別スキャン・自動探索
攻撃者はスキャンツールを使い、インターネット上の脆弱なポートを探索する。VPNアプライアンスの公開ポートはこのスキャンに必ず引っかかり、ターゲットリストに載り続けるリスクがある。 ダークIPではサーバーのIPアドレス自体がインターネット上に存在しないため、スキャンの対象にならない。AIによる自動スキャンが高度化している現在、この効果はより重要になっている。
VPNアプライアンス自体へのCVE直接攻撃(第3層対処の副次的効果)
IvantiやFortinetなどVPN製品に重大なCVEが発見されるたびに、公開ポートを持つアプライアンスが直接攻撃を受ける(第1層のリスク)。ダークIPは本来、第3層の設計思想の欠陥——公開ポートの恒常的な存在——を排除するためのアプローチだが、公開ポートがなくなることで攻撃者がCVEを突く糸口自体がなくなることになる。第3層への対処が第1層のリスクも連鎖的に軽減するという副次的な効果となる。
ビジネスサプライチェーン経由の侵入
取引先・委託先・子会社などを踏み台にして本体ネットワークに侵入する手口である。VPNでは委託先に広いネットワークアクセスを与えてしまうため、委託先が侵害されると本体にも被害が及びやすい。
ZTNAの最小権限アクセスと組み合わせることで、委託先のアクセスを特定のアプリのみに限定できる。侵入経路が限定されるため被害範囲を大幅に縮小できる。
VPNでは委託先にVPNアカウントを発行すると、ネットワーク全体への通路を開けることになる。委託先が侵害された場合、その通路を通じて攻撃者が内部を移動できてしまうリスクがある。ZTNAでは「ネットワーク全体ではなく、特定のアプリケーション・リソースへのアクセスのみ許可する」という設計のため、委託先が侵害されても攻撃者が到達できる範囲を許可されたアプリに限定できる可能性がある。
ZTNAでは以下のようなポリシーをアクセスごとに適用できる。なおZTNAの実装アーキテクチャの一形態であるSDP(Software Defined Perimeter)を採用することで、委託先のデバイスにエージェントをインストールしなくても、これらの制御を適用できる。
- アクセス先の限定: 委託先Aは保守対象サーバーのポート22(SSH)のみ、委託先Bは特定の業務アプリのみ、といった粒度で制御できる
- 時間・コンテキストによる制御: 接続時間帯・接続元地域・デバイスの健全性(EDR導入済みか等)を条件にアクセスを制限できる
- セッションの記録・監視: 委託先のアクセスセッションをログとして記録し、異常な操作を検知できる
- 退職・契約終了時の即時失効: 人事システムとの連携により、委託先の契約終了と同時にアクセス権を自動的に無効化できる(VPNで問題になるゾンビアカウントを防ぐ)
VPNが「委託先にネットワークへの扉を開ける」設計であるのに対し、ZTNAは「必要な窓口だけを、必要な期間だけ、必要な相手にだけ開ける」設計である。ビジネスサプライチェーン攻撃への対策として、ZTNAはVPNより構造的に優れているといえる。
ダークIPで防げないこと
認証通過後のアプリケーション層の脆弱性攻撃
ZTNAは「誰が・どのデバイスから・何に」アクセスするかを制御する。しかしアクセスを許可した後、そのアプリケーション内部にSQLインジェクションやバッファオーバーフロー等の脆弱性があれば、正規ユーザー経由で攻撃が成立してしまうリスクがある。 これはダークIPの問題ではなく、アプリケーション層のセキュリティの問題である。WAF(Webアプリケーションファイアウォール)・SAST・DASTなどの別の対策が必要になる。
ソフトウェアサプライチェーン攻撃
正規のソフトウェアアップデートにマルウェアを混入させる手口として、SolarWinds事件(2020年)がその代表例である。正規の署名付きアップデートとして配布されたため受け取った組織には見分けがつかない。 ZTNAからは「正規デバイス・正規ユーザー・正規ソフトウェア」として認識されてしまうため、ネットワークアクセス制御では防げない。ソフトウェアの完全性の検証はZTNAの対象外であり、SBOM(ソフトウェア部品表)管理・コード署名検証・EDRとの組み合わせが必要である。
内部不正
正規ユーザーによる意図的な悪用はZTNAのポリシー評価を通過してしまう。ただし最小権限の設計により、アクセスできるリソースが限定されるため被害範囲を縮小できる可能性はある。内部不正の防止には、行動監視(UEBA)・職務分掌・定期的なアクセス権レビューなど別の対策が必要となる。
「攻撃対象面の消去」ではなく「削減」
ZTNAの説明でしばしば「攻撃対象面(アタックサーフェス)をゼロにする」という表現が使われるが、これは正確ではない。ダークIPが実現するのは「外部からのスキャン・直接攻撃に対するアタックサーフェスの根本的な削減」である。
認証を通過した後のアプリ層・ソフトウェアサプライチェーン・内部不正といった脅威には効果が及びにくい。ZTNAはセキュリティの万能薬ではなく、多層防御の重要な一層として位置づけるべきである。 WAF・EDR・UEBA・SBOM管理などとの組み合わせが、ZTNAの効果を最大化する。
まとめ:効果の一覧
ここでは、以上の内容をまとめて、ダークIPの効果について以下の表にまとめた。
その他、ZTNAとして別途考慮すべき課題
以上、ZTNAのダークIPについてその効果、課題について整理した。ZTNAについては、その他にも考慮すべき課題がある。それらについて、技術的課題と管理的課題に分けて、深刻度順に整理したので参考にしていただきたい。なお、深刻度は筆者の個人的な評価である。
技術的課題(深刻度順)
- IdPの外部公開エンドポイント問題(深刻度:高)
ZTNAのコントロールプレーンであるIdP(EntraID・Okta等)はインターネットに公開されており、ダークIPの保護対象外である。IdPが侵害されるとポリシー全体が書き換えられ、ZTNAのアクセス制御が根底から機能しなくなるリスクがある。被害範囲が組織全体に及ぶ深刻なリスクであり、IdPの冗長化・MFA強化・Conditional Accessの設計を別途行う必要がある。 - 移行期のハイブリッド運用リスク(深刻度:高)
VPNとZTNAの並行運用期間中は両方の攻撃面が同時に存在する。VPNの公開ポートは残り続け、ZTNAのポリシーはまだ未成熟という状態が生まれやすい。移行設計を誤ると一時的にリスクが増大する逆転現象が起きうるため、段階移行の計画において最も注意が必要な期間である。 - デバイスポスチャ評価の限界(深刻度:中)
ZTNAはデバイスの健全性(EDR導入・パッチ状態等)をポリシー条件にできるが、ポスチャ評価は「既知の基準への適合」を確認するものであり、ゼロデイマルウェアに感染したデバイスが通過してしまう場合がありうる。「ポスチャチェックをしているから安全」という過信が最大のリスクとなる。最小権限設計で被害範囲は限定できるが、過信を防ぐことが重要である。 - セッション継続検証の実装の差(深刻度:中)
ZTNAの原則は「継続的な検証」であるが、製品によってはセッション確立後の再検証頻度が低いものがある。長時間セッション中にデバイス状態が悪化しても検知されない場合がありうる。製品選定時に再検証の頻度・トリガー条件を評価基準に含めるべきである。
管理的課題(深刻度順)
- ポリシー設計・維持の継続的負荷(深刻度:高)
最小権限ポリシーは「設計して終わり」ではなく、業務変化に合わせた継続的な見直しが必要である。放置されたポリシーはVPN同様の広範アクセスを許容することになりかねず、ZTNAを導入した意味が損なわれるリスクがある。さらに「ZTNAを入れているから安全だ」という誤った安心感を生みやすい点が深刻である。ポリシーレビューの頻度・体制・担当者スキルを運用設計に組み込む必要がある。 - 責任分界点の明確化(深刻度:高)
ZTNAをSaaSで利用する場合、セキュリティの責任がどこまでベンダー側にあるかを明確にする必要がある。インシデント発生時に責任の所在が不明確だと対応が遅れ被害が拡大するおそれがある。調査・対応における情報提供義務・ログへのアクセス権・SLAの内容を契約段階で確認すべきである。 - ベンダーロックインとガバナンス(深刻度:中)
ZTNAは標準化が未成熟であり製品間の相互運用性が低い。特定ベンダーに依存した構成になると乗り換えコストが高くなりうる。ベンダー選定時に「標準プロトコルへの準拠度」「データのポータビリティ」を評価基準に含めるべきである。後からの対処が困難な点で長期的なリスクが高い。 - ログの保全とコンプライアンス(深刻度:中・業種依存)
ZTNAのコントロールプレーンがSaaSで提供される場合、アクセスログがベンダーのクラウドに保存される。ログの保存期間・保存場所・アクセス権がISMS・個人情報保護法・金融規制等のコンプライアンス要件を満たすかを確認する必要がある。特に、金融・医療等の規制業種では深刻度が最上位になりうる。
以上