
クラウドネイティブにおける新しい責任共有モデルとセキュリティの考え方
2023年3月29日
CSAジャパン クラウドセキュリティ自動化WG 諸角昌宏
クラウドの責任共有モデルは、サービスモデル(IaaS, PaaS, SaaS)に基づいて説明されてきた。しかしながら、新たに登場してきたコンテナ、サーバーレス等を用いたクラウドネイティブの環境における責任共有モデルを考えた場合、既存のサービスモデルに基づいた考え方ではカバーしきれないのではないかという懸念がある。CSA Silicon Valley Chapterでは、クラウドネイティブにおける新しい責任共有モデルの考え方を説明した” The Evolution of Cloud Computing and the Updated Shared Responsibility”というブログを2021年2月に公開した。これはCSAジャパンにより日本語化され「クラウドコンピューティングの進化と新たな責任共有モデル」として公開されている。
ここでは、上記資料で説明されている新しい責任共有モデルに対して、CSAが公開した以下の資料におけるセキュリティの考え方を対応させることで、クラウドネイティブの責任共有モデルの考え方とそのセキュリティの考え方について統合して理解できるようにしたい。
- Best Practices for Implementing a Secure Application Container Architecture
日本語版「安全なアプリケーションコンテナアーキテクチャ実装のためのベストプラクティス」 - How to Design a Secure Serverless Architecture
日本語版「安全なサーバーレスアーキテクチャを設計するには」
なお、このクラウドネイティブの責任共有モデルは、標準として定められているものではなく、あくまで現段階における1つの考え方として提供されているものであるということは注意していただきたい。今後、NISTやISOにおいて、標準としてのクラウドネイティブの責任共有モデルが定義された際は、その標準に基づいて改めて考えていく必要がある。
- クラウドネイティブにおける新しい責任共有モデルの概要
ここでは、まずクラウドネイティブにおける新しい責任共有モデルについて、「クラウドコンピューティングの進化と新たな責任共有モデル」の下図を用いて説明する。なお、ここで記述されているモデルをここからは便宜上「CNCFモデル」と呼ぶことにする。また、ここでは要点だけ説明するので詳細は上記資料を参照していただきたい。なお、下図は上記資料では英語で表記されているが、分かりやすくするため日本語に翻訳して表記している。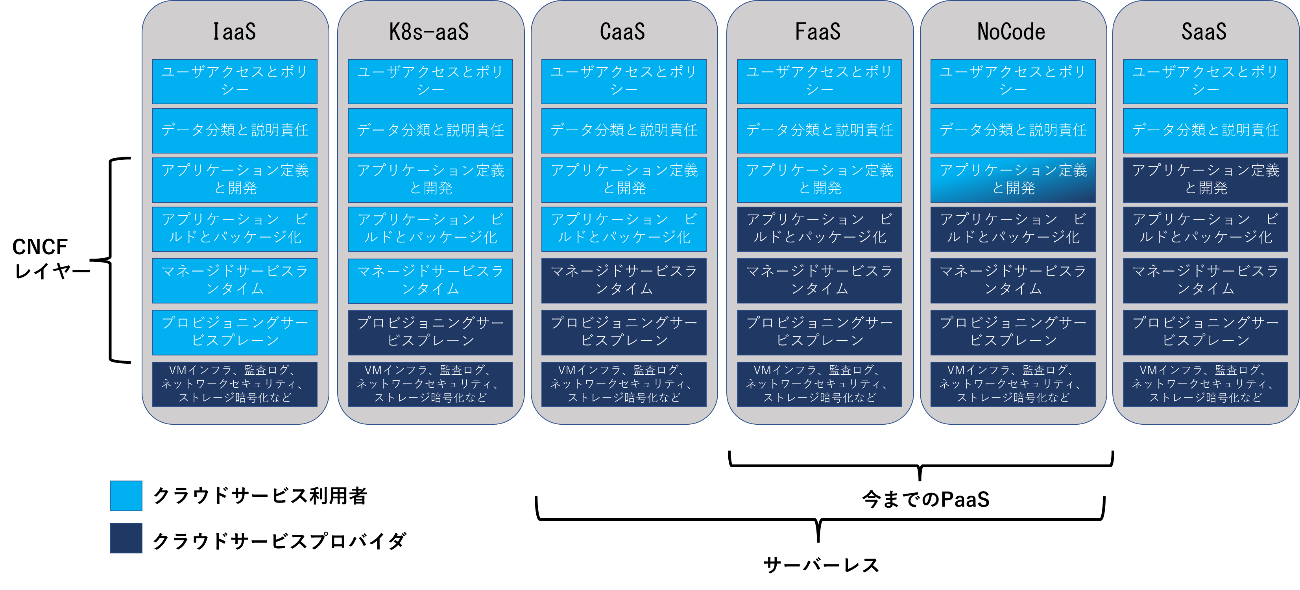
図1 CNCFモデル(「クラウドコンピューティングの進化と新たな責任共有モデル」より引用、作成)
図の左で「CNCFレイヤー」と記載されているのはCloud Native Computing Frameworkとして、既存のサービスモデルのレイヤーに新たに追加されたクラウドネイティブのレイヤーである。これらのレイヤーは以下の内容になる。
- プロビジョニングサービスプレーン
このレイヤーは、コントロールプレーンにあたる。ここでは、Kubernetesで説明されているが、Dockerコントロールプレーンでも同様に扱うことができる。プロビジョニングサービスプレーンでは、コンテナの稼働や停止等の運用や、コンテナの配置、デプロイ時のコンテナ入れ替えや仮想ネットワークの提供等を行う。
セキュリティの観点からは、コンテナのセキュリティを実装されるために必要となる機能およびアーキテクチャを提供するレイヤーとなる。
このレイヤーは、IaaSを除くすべてのモデル(K8s-aaS, CaaS, FaaS, NoCode, SaaS)においてプロバイダの責任となる。IaaSにおいては、このレイヤーにあたるKubernetesやDockerを利用者がインストール・設定・運用・管理を行うため、利用者側の責任となる。 - マネージドサービスランタイム
このレイヤーは、データプレーンにあたる。コンテナが稼働する実行環境、もしくはサーバーインスタンスそのもので、コンテナランタイムを管理する。コントロールプレーンが提供する機能を実際にコンテナランタイムに対して実施するレイヤーとなる。
サーバーレスの観点では、コントロールプレーンとデータプレーンの両方をプロバイダが管理することで、利用者はコンテナクラスタや仮想マシンなどのインフラストラクチャを管理しなくてもクラウドネイティブサービスに簡単に移行できるようになる。したがって、このマネージドサービスランタイムのレイヤーまでをプロバイダが管理するモデル(CaaS, FaaS, NoCode)がサーバーレスのモデルということになり、K8s-aaSはサーバーレスではないことになる(注:SaaSはアプリケーションを含むクラウド全体をプロバイダが管理するので、サーバーレスのカテゴリーからは除くこととする)。 - アプリケーションビルドとパッケージ化
このレイヤーは、コンテナイメージの作成、コンテナ環境への移動・実施といういわゆるビルドチェーンを管理する。クラウドネイティブの観点では、このレイヤーを利用者が管理する(CaaS)のか、あるいはプロバイダが管理する(FaaS, NoCode)のかということになり、サーバーレスの責任共有を考える上では重要なレイヤーとなる。後ほどサーバーレスの章で説明する「コンテナイメージベースのサーバーレス」(CaaS)と「機能ベース(ファンクションベース)のサーバーレス」(FaaS, NoCode)として、それぞれの責任を明確にすることが必要となる。 - アプリケーション定義と開発
このレイヤーは、アプリケーションのコードロジックを定義・開発する。アプリケーションの仕様と構成からコードを生成する際に、利用者が自身でコードロジックを作成する(FaaS)のか、あるいは、プロバイダが利用者の作成した仕様と構成からコードを生成する(No-Code)に分類される。クラウドネイティブの観点からは、この2つのモデルの差はあまりなく、FaaSの場合には利用者がビジネスロジックを直接コード化する(Python等を用いる)のに対して、No-Codeの場合にはプロバイダが提供するGUI等を用いてドラグ&ドロップなどによってコードロジックを作成する。No-Codeに対してLow-Codeという方法もありこれはGUIだけでなく一部のコードロジックについては直接作成する。
セキュリティの観点では、このレイヤーは基本的に利用者が管理を行うが、No-Codeの場合にはGUIを提供する部分がプロバイダの責任となる。責任共有の観点からはあまり区別する必要は無いと思われる。
- コンテナセキュリティ
ここでは、CSAが公開している「安全なアプリケーションコンテナアーキテクチャ実装のためのベストプラクティス」に基づいてコンテナセキュリティについて説明する。この資料では、コンテナのセキュリティについてアプリケーションの開発者および運用者の観点で書かれているので、上記のモデルのK8s-aaSを対象として考えるのが分かりやすい。つまり、この資料の登場人物である「開発者」を利用者、「運用者」をプロバイダと読み替えることで、K8s-aaSの責任共有モデルとして表現できる。- CNCFレイヤーとコンテナセキュリティ
まず、本資料で記述しているコンテナセキュリティの構成要素をCNCFレイヤーに対応付けると以下になる。- プロビジョニングサービスプレーン
プロビジョニングサービスプレーンを構成しているのは、プラットフォーム管理、コンテナ管理で、運用者がこれらの機能を提供している。 - マネージドサービスランタイム
プロビジョニングサービスプレーンで提供されている機能を用いて、開発者がコンテナランタイムの管理を実施する。 - アプリケーションビルドとパッケージ化、アプリケーション定義と開発
この2つのレイヤーは、アプリケーションの設計、開発、ビルド、実行を行うもので、開発者が管理する。
- プロビジョニングサービスプレーン
- コンテナセキュリティの内容
ここでは、コンテナセキュリティについて、主なポイントとなる点を説明する。詳細については上記資料を参照していただきたい。- 開発者のアプリケーションセキュリティ
- 開発環境全体(開発、品質保証、テスト、本番)のコードプロモーションのセキュリティ対策として、コンテナイメージに署名し信頼の起点(root of trust)を確立する。
- 開発プロセスの一部として脆弱性スキャンを行う。
- イメージの中には必要なコンポーネントのみを入れる。
- アプリケーションにログ機能、フォレンジック機能を含める。
- アプリケーションにシークレット管理機能を取り込む。
- コンテナイメージの暗号化、保存データの暗号化を行う。
- 運用者のアプリケーションセキュリティ
- ビルドチェーンの完全性を確保するため、デジタル署名を使用し検証するための機能を提供する。
- 署名され承認されたイメージだけを使用許可するための機能を組み込む。
- 運用者のホストセキュリティ(ホストセキュリティは開発者は無し)
- 通信の暗号化を行う。
- コンテナを特権モードで実行しない。
- 基本的に、コンテナランタイムにホストファイルシステムへのアクセスを許可しない。
- 限定的なcapability設定でコンテナを起動する。ユーザが必要な機能以外を使用できないようにする。
- 開発者のプラットフォームセキュリティ
- コンテナで実行されるアプリケーションのバージョン管理を行う。
- 運用者のプラットフォームセキュリティ
- ログの送信、集中管理の基盤を提供する。
- コンテナのライフサイクル(起動から破棄まで)のイベントを開発者に通知できるようにする。これにより、開発者は適切な対応が取れるようになる。
- リソースの消費を監視し、最適化する。
- 開発者のコンテナセキュリティ
- ホストとコンテナ間の通信の機密性(暗号化)および双方向TLS等の相互認証メカニズムを使用する。
- ネットワーク監視機能を使用する。
- コンテナのフォレンジック機能、ログ機能を、アプリケーションにログ機能を含める。
- データのバックアップとして、データの保存場所の特定、バックアップの定期的な実施、また、コンテナが消滅する前にバックアップされることを確認する。
- 運用者のコンテナセキュリティ
- ホストとコンテナ間の通信の機密性(暗号化)および双方向TLS等の相互認証メカニズムを提供する。
- コンテナのフォレンジック機能、ログ機能を提供する。
- コンテナのトラストチェーンの維持。OS およびコンテナイメージの完全性検証、脆弱性検査を実施する。
- コンテナのリソース管理、ボリューム監視を行う。
- 通信トラフィックの分離を行う。
- シークレット管理機能を提供する。
- データのバックアップとして、データの保存場所の特定、バックアップの定期的な実施、また、コンテナが消滅する前にバックアップされることを確認する。
- 開発者のアプリケーションセキュリティ
- CNCFレイヤーとコンテナセキュリティ
以上のようなポイントを考慮してコンテナのセキュリティを考えていくことが必要である。
- サーバーレスセキュリティ
サーバーレスは、CNCFモデルではCaaS, FaaS, No-Codeの各モデルが対象となる。サーバーレスのセキュリティとしてCSAが公開している資料は、「安全なサーバーレスアーキテクチャを設計するには」であり、ここではこの資料とCaaS, FaaS, No-Codeの各モデルをマップして説明する。サーバーレスセキュリティの基本的な考え方は、クラウド利用者(注:「安全なサーバーレスアーキテクチャを設計するには」では「アプリケーションオーナー」と表記)がデータの保護およびアプリケーションの保護のみの責任を持つ。一方、クラウドプロバイダ(注:「安全なサーバーレスアーキテクチャを設計するには」では「サーバーレスプラットフォームプロバイダ」と表記)がサーバーの立ち上げ、OSのパッチ適用、アップデート、シャットダウンなどのサーバーやそのセキュリティの管理の責任を持つ。これにより、アプリケーションオーナーはインフラの管理を気にせずにアプリケーションに集中することができる。「安全なサーバーレスアーキテクチャを設計するには」では、サーバーレスを2つの名称に分けて表現しており、1つは「コンテナイメージベースのサーバーレス」で、もう1つが「機能ベース(ファンクションベース)サーバーレス」である。この2つの名称をCNCFモデルに当てはめると以下のようになる。- コンテナイメージベースのサーバーレス: CaaS
- 機能ベースのサーバーレス: FaaS, No-Code
機能ベースのサーバーレスにFaaS, No-Codeの2つのモデルを当てはめているが、FaaS, No-Codeの違いは「アプリケーション定義と開発」レイヤーにおける責任の一部の違いであり、サーバーレスのセキュリティを考える上では同じものとして扱うことで問題ないと考える。
これをCNCFレイヤーとサーバーレスのセキュリティを対応付けると以下になる。
- アプリケーションビルドとパッケージ化
コンテナイメージベースのサーバーレス(CaaS)ではアプリケーションオーナー(利用者)の責任となるが、機能ベースのサーバーレス(FaaS, No-Code)ではサーバーレスプラットフォームプロバイダ(プロバイダ)の責任となる。 - アプリケーション定義と開発
コンテナイメージベースのサーバーレス(CaaS)、機能ベースのサーバーレス(FaaS, No-Code)のどちらにおいても利用者の責任となる。
この責任の考え方については、「安全なサーバーレスアーキテクチャを設計するには」で表現されている以下の2つの図が分かりやすい。「コンテナイメージベースのサーバーレス(注:この図では「イメージベースのサーバーレスの責任共有モデル」と表現)」(左図)では、コンテナイメージの責任がアプリケーションオーナー、つまりクラウド利用者となっているのに対して、「機能ベースのサーバーレス(注:この図では機能ベースのサーバーレス(FaaS)の責任共有モデル」と表現)」(右図)では、このコンテナイメージの責任がサービスプロバイダとなっている。この違いは、CNCFモデルにおける「アプリケーションビルドとパッケージ化」レイヤーの責任の違いとなる。
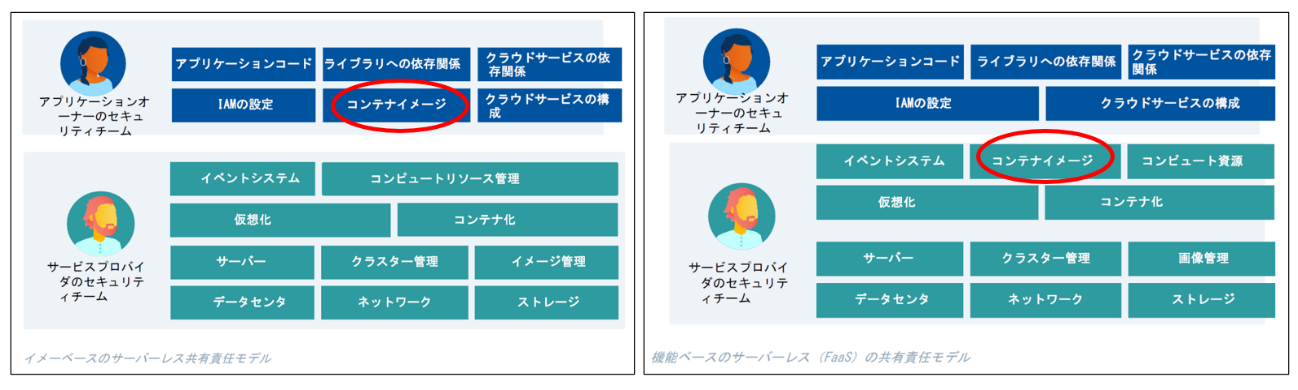
図2 「安全なサーバーレスアーキテクチャを設計するには」より引用
なお、これらをAWS、Azure、Googleのサービスに照らし合わせると以下になる。
- コンテナイメージベースのサーバーレス(CaaS)
AWS Fargate、Azure Container Instances(ACI)、GoogleCloudRunなど - 機能ベースのサーバーレス(FaaS, No-Code)
FaaS: AWS Lambda、Azure Functions、Google CloudFunctions
No-Code: Azure Power Apps、Google AppSheet、AWSHoneycode
これをCNCFレイヤーとサーバーレスのセキュリティを対応付けると以下になる。
- アプリケーションビルドとパッケージ化
コンテナイメージベースのサーバーレス(CaaS)ではアプリケーションオーナーの責任となるが、機能ベースのサーバーレス(FaaS, No-Code)ではプロバイダの責任となる。 - アプリケーション定義と開発
コンテナイメージベースのサーバーレス(CaaS)、機能ベースのサーバーレス(FaaS, No-Code)のどちらにおいてもアプリケーションオーナーの責任となる。
「アプリケーションビルドとパッケージ化」におけるセキュリティは、「2. コンテナセキュリティ」で説明した内容となるのでそちらを参照していただきたい。あくまで、これがアプリケーションオーナーの責任になるかプロバイダの責任になるかの違いである。
「アプリケーション定義と開発」におけるセキュリティについて、「安全なサーバーレスアーキテクチャを設計するには」では、アプリケーションオーナー(つまり、利用者)のセキュリティとして、ワークロードへの脅威の観点で以下の3点を挙げている。
- セットアップフェーズの脅威
アプリケーションオーナーがワークロードを準備し、コード、イメージ、CI/CD作業、デプロイに関する脅威のことを言う。最小特権原則を維持していない呼び出し、およびセキュアでない構成管理の問題となる。
サーバーレスにおいてはワークロードが小さな呼び出し可能なユニットに分割され、それぞれにセキュリティを管理する一連のパラメータ(ユーザの認証情報/アクセス件、呼び出し可能なユニットの認証情報/アクセス権、モニタリングなど)が設定される。これらに対して、最小権限の原則を維持することが必要である。また、この分割が増えることで、サプライチェーンの脆弱性の問題が起こる。ベースイメージの脆弱性、リポジトリに対する不正アクセス、ビルド/デプロイツールに対する攻撃などへの対応が必要である。 - デプロイフェーズの脅威
アプリケーションオーナーによるワークロードのデプロイフェーズでの脅威のことを言う。
サーバーレスでは、様々なリソースからの膨大なイベントを利用する。イベントの一部として呼び出し可能なユニットに渡される情報はデータインジェクションの脅威となる。また、呼び出し可能なユニットが必要とするトークン、シークレットなどはグローバルコンテキストを必要とし、このグローバルコンテキストのリークが発生する脅威がある。
また、サーバーレスで使用するコンピュートリソースは従量課金であるため、適切な感じと処理を行わないとリソースの枯渇等の問題が発生する。
サーバーレスのワークロードは、データと制御パスの一部をサービスプロバイダにオフロードするため、開発とテストをクラウド上で行う必要がある。デバッグなどが制限される可能性もある。したがって、エラーメッセージが重要になる。 - サービス事業者による脅威
サービスプロバイダが使用するコンポーネントスタック全体および関連サービスの脅威が含まれる。
まず重要なのがマルチテナントを維持するための隔離の問題である。サーバーレスでは、プロバイダが分離を確立する必要がある。また、インスタンスの起動/終了のオーバーヘッドを削減するために呼び出し可能なユニットの再利用を行う場合があるため、呼び出し可能なユニットの呼び出し間の漏洩および残留データの漏洩というサーバーレス固有の脅威もある。
また、責任共有の問題として、サーバーレスではコードの設計、ランタイムのセキュリティの責任をアプリケーションオーナーが持つが、その中で機能ベースのサーバーレスの場合、プロバイダが提供する呼び出し可能なユニットの脆弱性が発生する可能性がある。コードの設計やイベントシステムのセキュリティだけでなく両者の相互作用についても考える必要がある。
以上が、アプリケーションオーナーのワークロードへの脅威の観点でのサーバーレスのセキュリティとなるが、「安全なサーバーレスアーキテクチャを設計するには」ではKubernetesのセキュリティからアプリケーションのセキュリティまでを詳細に記述している。Kubernetesのセキュリティは、「2. コンテナセキュリティ」でも記述されている部分になるが、より詳しくKubernetesの機能に基づいて記述しているので、参照していただきたい。
- まとめ
以上、CNCFモデルをベースに、CSAが公開しているコンテナおよびサーバーレスのセキュリティに関する資料を参照しながら説明してきた。コンテナのセキュリティについては整理されてきているが、サーバーレスについてはまだ適切なセキュリティが明確になっていない。今後、様々な形で情報が提供されてくるので、それを見ていきながらサーバーレスとしてまとまった形でのセキュリティについて説明できるようにしていきたい。
以上